Review of DNA Replication and the Central Dogma
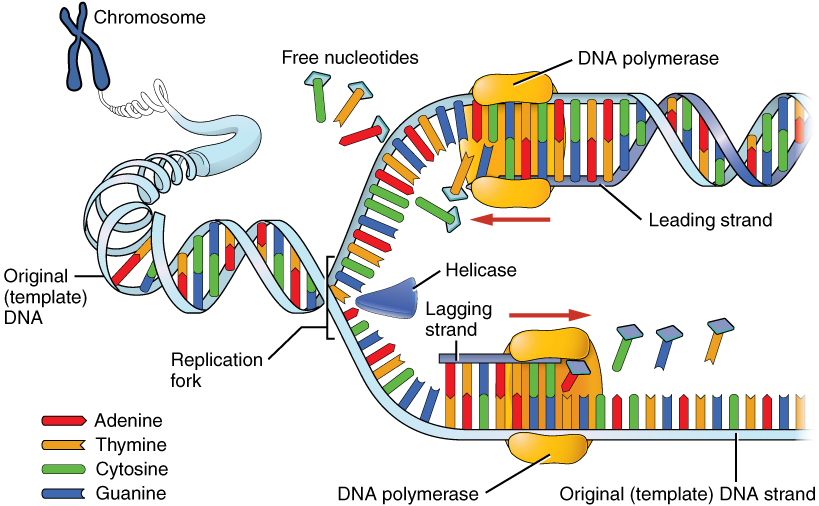
DNA replication is a fundamental biological process that ensures the faithful transmission of genetic information from one generation to the next. The process is semi-conservative, meaning each new DNA molecule consists of one original (parental) strand and one newly synthesized strand. This process occurs during the S phase of the cell cycle. The replication of DNA involves several key steps:
- Initiation:
-
- Origin of Replication: Replication begins at specific sites called origins of replication.
- Helicase: An enzyme called helicase unwinds the DNA helix, creating a replication fork.
- Primase: The enzyme primase synthesizes a short RNA primer complementary to the DNA template to provide a starting point for DNA synthesis.
- Elongation:
-
- DNA Polymerase: DNA polymerase adds new nucleotides to the 3′ end of the RNA primer, extending the new DNA strand.
- Leading and Lagging Strands:
- The leading strand is synthesized continuously in the direction of the replication fork.
- The lagging strand is synthesized discontinuously, creating short fragments called Okazaki fragments.
- DNA Ligase: DNA ligase joins the Okazaki fragments to form a continuous strand.
- Termination:
-
- Replication terminates when replication forks meet or when specific termination sequences are encountered.
- The RNA primers are removed and replaced with DNA, and any gaps are sealed.
DNA replication is remarkably accurate, but errors can occur. The fidelity of replication is maintained through several mechanisms. DNA polymerases have proofreading abilities, allowing them to remove incorrectly paired nucleotides immediately after they are added. DNA polymerases have a natural ability to detect when an incorrect nucleotide has been incorporated. This detection is largely based on the instability of a mismatch within the DNA double helix. The correct pairing of DNA bases (adenine with thymine, and cytosine with guanine) forms stable hydrogen bonds, while incorrect pairings do not fit properly and disrupt the helical structure. Many DNA polymerases also have an intrinsic 3’ to 5’ exonuclease activity. This means that when a mismatch is detected, the polymerase can reverse its direction, remove the incorrect nucleotide (exonucleolytic cleavage), and then resume DNA synthesis. This proofreading activity is crucial for correcting errors. Once the incorrect nucleotide has been excised, the DNA polymerase repositions itself back at the 3’ end of the newly synthesized strand and continues to add the correct nucleotides, ensuring the fidelity of the DNA replication process. Despite these mechanisms, replication errors do occasionally occur, leading to mutations.
- Considering the role of DNA polymerase’s exonuclease activity in maintaining replication fidelity, what might be the consequences for a cell if this proofreading mechanism was genetically disabled or inhibited by a chemical agent? How could this impact genetic stability and the overall health of an organism?
- DNA replication is tightly regulated and occurs during the S phase of the cell cycle. Why is the timing of replication critical for cellular function and genetic integrity? What potential problems could arise if DNA replication occurred at multiple points throughout the cell cycle?
The Central Dogma of Molecular Biology describes the flow of genetic information within a biological system. It is a framework that describes the flow of genetic information within a biological system. Articulated by Francis Crick in 1958, it outlines the process by which genetic information is transferred from DNA to RNA and then to protein. This fundamental concept consists of three main processes: replication, transcription, and translation, each interconnected and essential for the expression of genes.
- Replication: The process by which DNA makes a copy of itself (covered earlier).
- Transcription: The process of converting DNA into RNA. Transcription is the first step in the gene expression process, where the sequence of a gene is copied from DNA to messenger RNA (mRNA). RNA polymerase, an enzyme, binds to a specific sequence on the DNA called the promoter, located at the beginning of a gene. This binding unwinds the DNA segment, and RNA polymerase reads the DNA template strand to synthesize a single-stranded RNA molecule with a nucleotide sequence complementary to the DNA template. Unlike in DNA, the RNA nucleotide uracil (U) is used instead of thymine (T), pairing with adenine. Once the mRNA molecule is synthesized, it undergoes processing where introns (non-coding regions) are removed, and a cap and tail are added to stabilize the mRNA before it exits the nucleus.
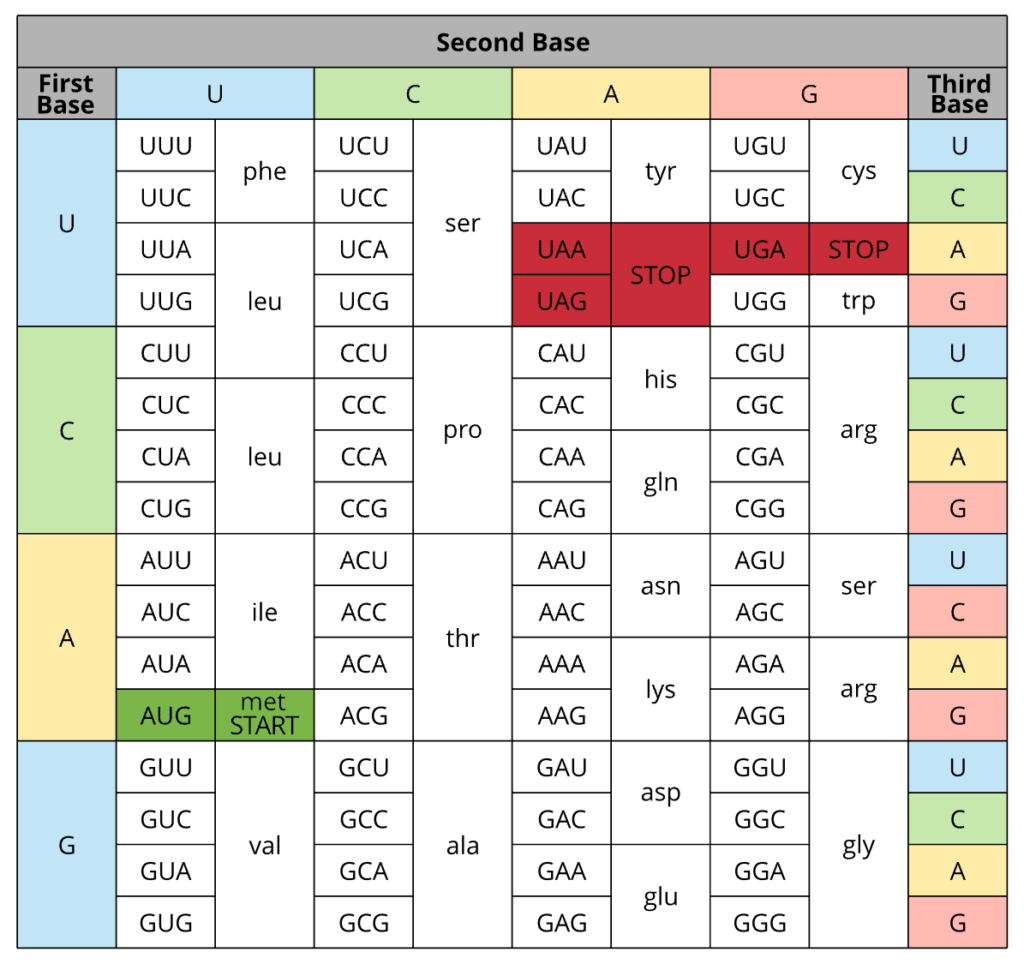
- Translation: The process of synthesizing proteins based on the sequence of an mRNA molecule. Translation is the process by which the genetic code carried by mRNA is decoded to produce a specific sequence of amino acids, ultimately resulting in a polypeptide chain that folds into a functional protein. This occurs in the ribosome, a complex machine in the cell that facilitates the docking of mRNA and the transfer RNA (tRNA) molecules that carry amino acids. Each three-nucleotide sequence (codon) on the mRNA corresponds to one amino acid, as specified by the genetic code. For example, the codon AUG codes for the amino acid methionine and also serves as the start signal for translation. As the ribosome moves along the mRNA, tRNA molecules match their complementary anticodon sequences to the mRNA codons, bringing the appropriate amino acids into place. The ribosome catalyzes the formation of peptide bonds between the amino acids, elongating the polypeptide chain until it reaches a stop codon, which does not code for an amino acid but signals the end of translation.
Finally, the standard genetic code specifies the basic rules by which the nucleotide sequence of mRNA is translated into the amino acid sequence of proteins. It is nearly universal across all organisms, underlining the evolutionary continuity and common origin of life (there are exceptions). The genetic code is redundant, meaning that most amino acids are encoded by more than one codon, providing some tolerance against mutations. This code ensures that genetic information is translated with remarkable precision into the diverse array of proteins that perform various functions within the cell.
Media Attributions
- 0323_DNA_Replication © OpenStax
- Central_dogma_of_molecular_biology_colorized+special_transfer(1) © Philippe Hupé is licensed under a CC BY-SA (Attribution ShareAlike) license
- codon chart © Scott Henry Maxwell is licensed under a CC BY-SA (Attribution ShareAlike) license

{kind=link}
{kind=link}
{kind=link}